Demos
Deep Learning
Deep Redundancy
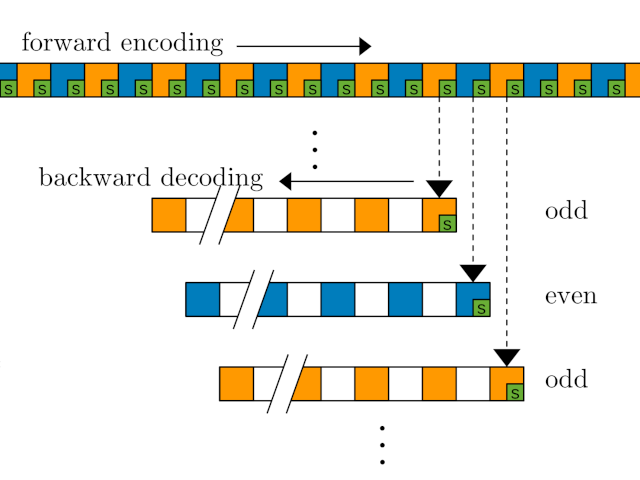
We demonstrate a Deep REDundancy (DRED) model that makes Opus much mode robust to packet loss. DRED makes it possible to transmit every audio frame up to 50 times with just 32 kb/s of overhead. That makes it possible to fill in the missing audio even when transmission gets interrupted for one full second.
PercepNet
We introduce the PercepNet algorithm, which combines signal processing, knowledge of human perception, and deep learning to enhance
speech in real time. PercepNet ranked second in the real-time track of the Interspeech 2020 Deep Noise Suppression challenge,
despite using only 5% of a CPU core.
LPCNet 1.6 kb/s Codec

In this demo, we turn LPCNet into a very low-bitrate neural speech codec that's actually usable on current hardware and even on phones. It’s the first time a neural vocoder is able to run in real-time using just one CPU core on a phone (as opposed to a high-end GPU).
LPCNet
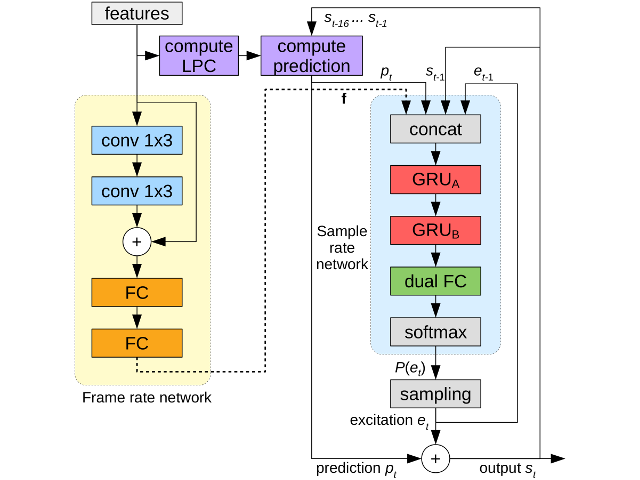
This demo presents the LPCNet architecture that combines signal processing and deep learning to improve
the efficiency of neural speech synthesis. It explains the motivations for LPCNet, shows what it can achieve,
and explores its possible applications.
RNNoise
This demo presents the RNNoise project, showing how deep learning can be applied to noise suppression.
The main idea is to combine classic signal processing with
deep learning to create a real-time noise suppression algorithm that's small and fast.
The result is much simpler and sounds better than traditional noise
suppression systems.
Opus Audio Codec
Opus 1.3

This demonstrates the improvements and new features in Opus 1.3, including better speech/music detection,
ambisonics support, and low-bitrate improvements.
Opus 1.2

This demonstrates the improvements and new features in Opus 1.2 compared to
version 1.1. It also includes audio samples comparing to previous versions of
the codec.
Opus 1.1

This describes the quality improvements that Opus 1.1 brought over
version 1.0, including improved VBR, tonality estimation, surround
improvements, and speech/music classification.
Daala Video Codec
Revisiting Daala Technology Demos

This demo revisits all previous Daala demo. With pieces of Daala being contributed to the Alliance for Open Media's
AV1 video codec, we go back over the demos and see what worked, what didn't, and what changed compared to the description we made in the demos.
A Deringing Filter For Daala... And Beyond

This demo describes the new Daala deringing filter that replaces a
previous attempt
with a less complex algorithm that performs much better. Those who like to
know all the math details can also check out the
full paper.
Perceptual Vector Quantization (PVQ)
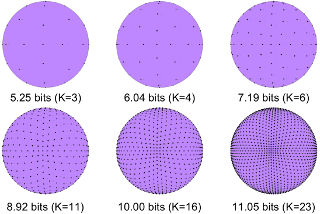
This demonstrates the Perceptual Vector Quantization technique currently
used in Daala and inspired from the Opus codec.
Painting Images For Fun (and Profit?)

This demonstrates a technique that turns images into what looks like
paintings. The application for this is intra prediction and deringing filtering
for the Daala video codec. Because of complexity issues, it was never adopted
in Daala, but inspired a new deringing filter that landed in Sep. 2015.
Microphone Arrays for Mobile Robots (Ph.D project)
Startacus attending the 2005 AAAI conference

This shows the Spartacus robot participating in the 2005 AAAI challenge.
Spartacus includes noise-robust sound localization and separation capabilities.
Sound Source Separation demo (2004)

This is an example of separating 3 simultaneous sound sources using
an array of 8 microphones.
Sound localization demo

In this video, the robot is controlled only by sound localization.
It turns towards the sound source that has been present for the longest amount
of time and moves towards it.
Older sound localization movie (IROS 2003)

This shows localization capabilities using an array of 8 microphones
mounted at the vertices of an empty cube. This video was presented at IROS 2003.