

Over the last three years, we have published a number of Daala technology demos. With pieces of Daala being contributed to the Alliance for Open Media's AV1 video codec, now seems like a good time to go back over the demos and see what worked, what didn't, and what changed compared to the description we made in the demos.

Our very first demo introduced lapping, one of the key Daala techniques that was meant to avoid the infamous blocking artifacts, while avoiding the IPR issues around adaptive deblocking filters. What made the idea appealing is that it did not require any clever adaptation (compared to deblocking filters that have to be finely tuned), while providing even more reduction in blocking artifacts. On top of that, it made the resulting transform more efficient than the DCT, and results in cleaner edges.
So what's not to like about lapped transforms? After all, audio codecs have been using them forever (though the MDCT is a slightly different type of lapped transform). with great results. Lapping — by itself — works pretty well. Most of the complications come from the fact that it interacts with almost all other pieces of the codec. More specifically:
Aside from the fact that Daala now uses only 4-point lapping everywhere, the way the lapping is implemented is still the same as described in the demo.
The verdict: The jury is still out. There are important pros and cons so more research is required. In the end, the use of lapping would have to depend on the other technologies around it. In terms of the Alliance for Open Media, using lapping is unlikely as it would require a large amount of changes to the baseline codec, significantly delaying the schedule.

The idea behind frequency-domain intra prediction is to overcome the complications caused by lapping by predicting transform coefficients directly instead of pixels. Blocks of transform coefficients are still independent. It's not obvious how to make directional predictors like "extend this edge diagonally down and to the right" in the frequency domain, but we just threw machine learning at it and let the computer build computationally efficient linear predictors for us. The idea was pretty neat and early experiments on 4x4 blocks looked promising. Then the problems started piling up:
The verdict: We had to abandon frequency-domain intra prediction as it failed to produce good results despite all the effort spent trying to make it work. It was replaced by a combination of Haar DC and a trivial predictor that only works for purely horizontal or vertical patterns.
The idea for time-frequency resolution switching (or just TF) came from the Opus codec, where it is used to get the best characteristics from both short blocks and long blocks. In the context of Daala, there were many goals:
The verdict: We've mostly abandoned time-frequency switching outside of chroma from luma. It's not that it failed, but many of the ideas would require a lot of work and so far the potential gains appear limited.

Chroma from luma (CfL) prediction is a rather simple idea: take advantage of the fact that edges in the chroma plane are usually well correlated with those in the luma plane. CfL is especially useful when you don't have intra prediction. Because it does not need the pixels from the adjacent block, it does not suffer from too many complications due to lapping. The actual way we implement CfL in Daala has changed significantly since the demo was written. Unlike intra prediction that turns out to be incompatible with another technology we chose (lapping), CfL really benefits from another technology — perceptual vector quantization (below) — which removes the need for the complicated (and sometimes unreliable) least squares fit described in the demo.
The verdict: Chroma from luma prediction is here to stay. It's quite simple to compute and gives good benefits.

If at first you don't succeed, try, try, try again. This is why we worked on the paint algorithm. The original idea was to create a tiny codec inside the codec, whose only purpose was to efficiently code highly directional patterns that usually benefit from intra prediction. Then we could use this as our prediction in the rest of the codec. And it could indeed produce impressive results at very low bitrate on images with lots of hard edges. The problem is that it didn't mix well with the rest of the codec. Attempting to code the remaining details not captured by the intra paint mini-codec ended up costing as many bits as coding the image from scratch. Although it was still (marginally) useful in regions with lots of edges, there was no simple way to turn it on or off, since it operated with a different block grid (with different overlap) than the transform grid.
It appeared that all was not lost for the paint algorithm, as we could still use it as a post-processing step rather than a predictor. In that case, there was no need to code any information, as it was used to enhance the edges of an already coded image. By controlling how much enhancement to apply, we could turn the paint algorithm into a deringing filter. The resulting deringing filter produced a noticeable improvement in quality, even if it didn't improve objective metrics very much (which is OK). But it was never merged into Daala. The problem is that the algorithm was not only expensive, but it proved nearly impossible to vectorize (i.e. implement with SIMD instructions like SSE, AVX, or Neon). That made it a dead-end.
The verdict: Nice try, better luck next time. There may be uses for intra paint as a photo filter, or even (who knows) as a stand-alone codec for certain types of images, but not as an intra predictor or as a deringing filter in a video codec.
At first, there was the Pyramid Vector Quantizer used in the Opus audio codec. It had some nice perceptual properties that we thought might be useful for video coding, so we implemented PVQ in Daala. Compared to the usual scalar quantization done traditional video codecs, Daala's PVQ offers a lot more flexibility to control quantization, making it possible to do things like activity masking easily, and without any extra signaling. The flexibility also comes at a cost: tuning knobs — lots of tuning knobs. With scalar quantization, all you have is a quantization step size (possibly a matrix) and a lambda for rate-distortion optimization. With PVQ, you also have different lambdas for block size selection and quantization, per-band parameters like the companding exponents (beta) and quantizer scaling factors, and many possible variants for how to choose the codebook size (K).
PVQ also has properties that simplify things. For example, the chroma from luma (CfL) predictor described above became much simpler when rewritten for PVQ. Because PVQ treats the gain (contrast) separately from the shape (details), it can deal easily when you have the right shape, but the wrong contrast, as is the case for CfL. This should also make it easier to handle fades, although we have not really experimented with those yet. In terms of performance, the fact that Daala is currently pretty good on still images (keyframes) — where PVQ does most of the job — indicates that it's working well.
We are currently working on bringing PVQ to AV1. It is no simple task because PVQ interacts with many other parts of a codec. It requires transforming the prediction, it changes how skip flags are coded, and the current Daala implementation depends on the multi-symbol entropy coder (see below), and differs from AV1 in how it does its rate-distortion optimization.
The verdict: While complicated, PVQ looks promising so far.

The next demo doesn't document a feature, but a bug. In early 2015, we started noticing that under special circumstances, the lapping filters can produce strange patterns. It took some time to understand that these patterns were caused by successive accumulation of "noise" coming from the interaction between the lapping filters and the rounding that was taking place when the 12-bit "intermediate" images were being rounded down to 8 bits for use as reference in future frames. Trying to change how the rounding was done or how the lapping was done went nowhere, originally causing some concerns over the viability of lapping itself. Fortunately, two solutions eventually emerged. One was to simply store all reference frames in 12 bits rather than 8. This requires more memory and more memory bandwidth, but also improves coding efficiency for all sequences (even those that did not trigger the problem). It's something that's also needed anyway for 10-bit and 12-bit input support. Another solution also emerged — mostly by accident — when we decided to try the Thor constrained low-pass filter (CLPF) in Daala. The CLPF is a very simple filter designed to reduce "artifacts introduced by quantization errors of transform coefficients and by the interpolation filter". As a side effect, we realized that the CLPF was also eliminating all of our unwanted rounding-related patterns. Since then, we have replaced the CLPF by the directional deringing filter (see below) that also solves the problem. The verdict: Problem solved.

The intra-paint-based deringing filter came close to succeeding... but didn't. Its replacement, the Daala directional deringing filter is still a bit new to "revisit", but it looks like it's going to succeed. Its complexity is far lower than the paint deringing filter, it's easy to vectorize, and — most importantly — it's providing a big improvement to both Daala and AV1.
The verdict: Success — so far anyway.
Daala includes even more unconventional technology than what made it to the demos so far. We still have overlapped block motion compensation (OBMC) and multi-symbol entropy coding that have yet to make it to a demo page, but let's "revisit" (or shall I say "visit") them anyway. OBMC in Daala is closely related to lapping. While lapping eliminates blocking artifacts from the transform (DCT) blocks, OBMC eliminates blocking artifacts from motion vector blocks. In traditional video codecs, both types of blocking artifacts would be eliminated by the deblocking filter, but since Daala does away with that, we need to avoid blocking for both the transform and the motion compensation. Despite having little in common mathematically, many of the consequences of lapping and OBMC are related. Like lapping, OBMC reduces blocking and improves theoretical coding efficiency. Its drawbacks are also similar: it makes the motion search difficult, it makes joint coding of motion vectors with transform flags impossible, and its wider spatial support causes issues with edges. One practical search-related problem is that Daala sometimes spends bits to improve motion vectors in an area — only to find out later that the PVQ coefficient coder has decided to throw the prediction away because it's still not good enough. The verdict: The jury is still out on OBMC as well. Its fate is closely related to that of lapping and to whether we find a way to solve search-related problems.
The multi-symbol entropy coder is not new to Daala. That's what Opus and many other codecs use. It's only new in the sense that previous video codecs have been restricting themselves to binary arithmetic coding. The use of binary arithmetic coding in standards like H.264 and HEVC has led to a large number of patents around binary context adaptation. This is not the only reason why Daala chose to go with non-binary though. Arithmetic coding is fundamentally serial, so symbols must be decoded one at a time (from a single thread), which slows down the decoding process. The entropy coder currently used in Daala supports alphabet sizes (the number of possibilities for a given symbol) up to 16, which means we can reduce the total number of symbols we encode by up to a factor of 4. That reduces the time it takes to decode the streams, allowing hardware decoders to run at a lower clock rate, saving power. Our entropy coder is also very general, allowing the sum of all probabilities to be any integer ≤ 32768, not only a power of two. Recent work attempting to both reduce the CPU complexity and improve the efficiency of the entropy coder has resulted in many different encoding and adaptation variants, with dozens of possible combinations. For example, we can have very efficient encoding when the probabilities sum to a power of two, at the cost of more complex adaptation, or we can have really simply adaptation with a less efficient non-power-of-two probability sum. We have yet to decide on the exact path, but fortunately the high-level way we use the entropy coder does not change. We are also working on implementing multi-symbol entropy coding in AV1. The verdict: So far it looks like multi-symbol entropy coding is the way to go, but which exact combination of variants is ideal is still an open question.

It has been a year and a half since Monty last presented a general progress update on Daala, so it's time for an update. First, let's look at some rate-distortion curves. The figure below shows the improvement on video since last update.
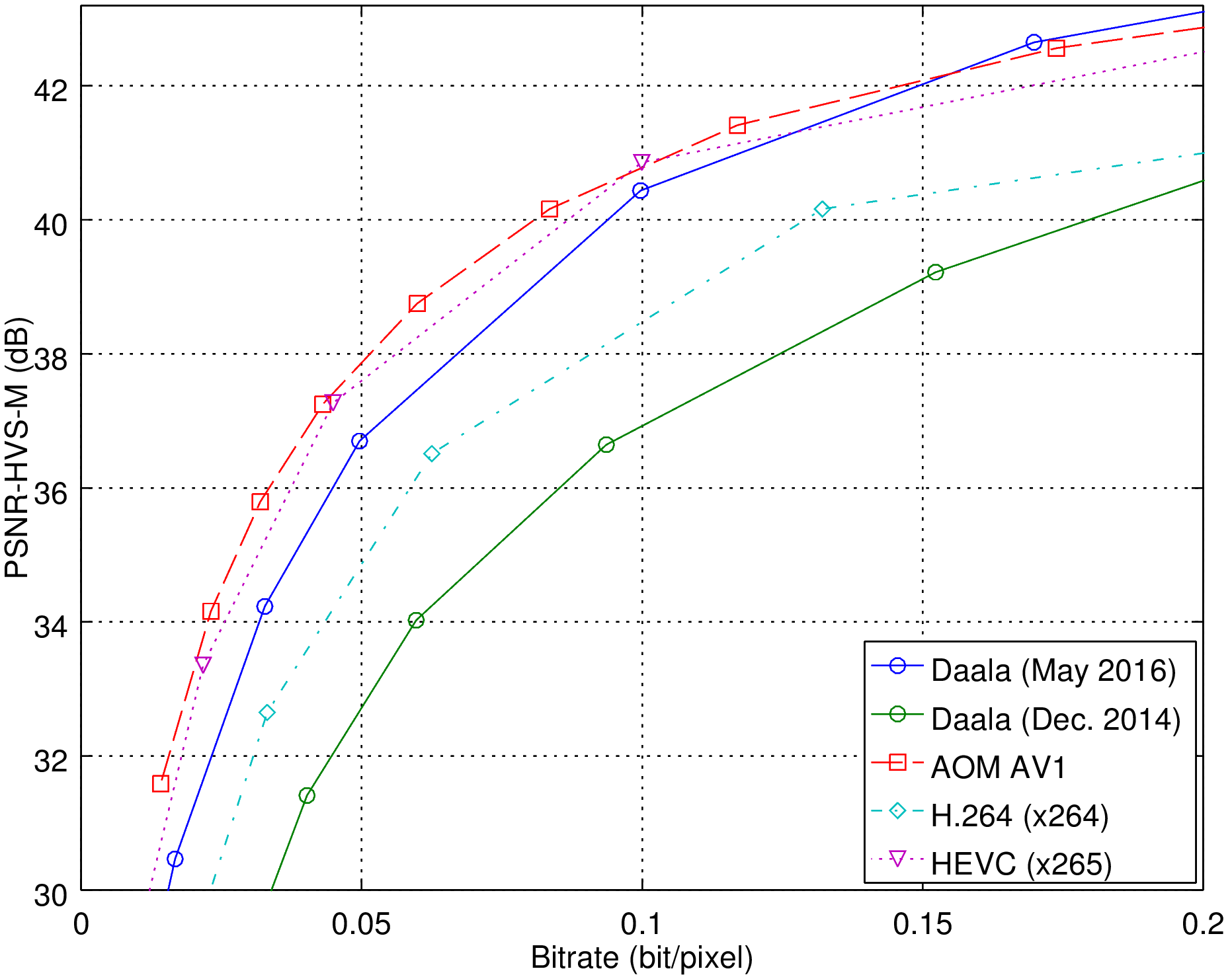
In about 18 months, Daala files got 50% smaller for equal quality, going from worse than H.264 to almost as good as HEVC and AV1. Not bad, especially considering that in the figure above, HEVC and AV1 are using B-frames and alt-refs, whereas Daala's (relatively immature) B-frames are turned off.
Now, let's look at how Daala improved on still images:
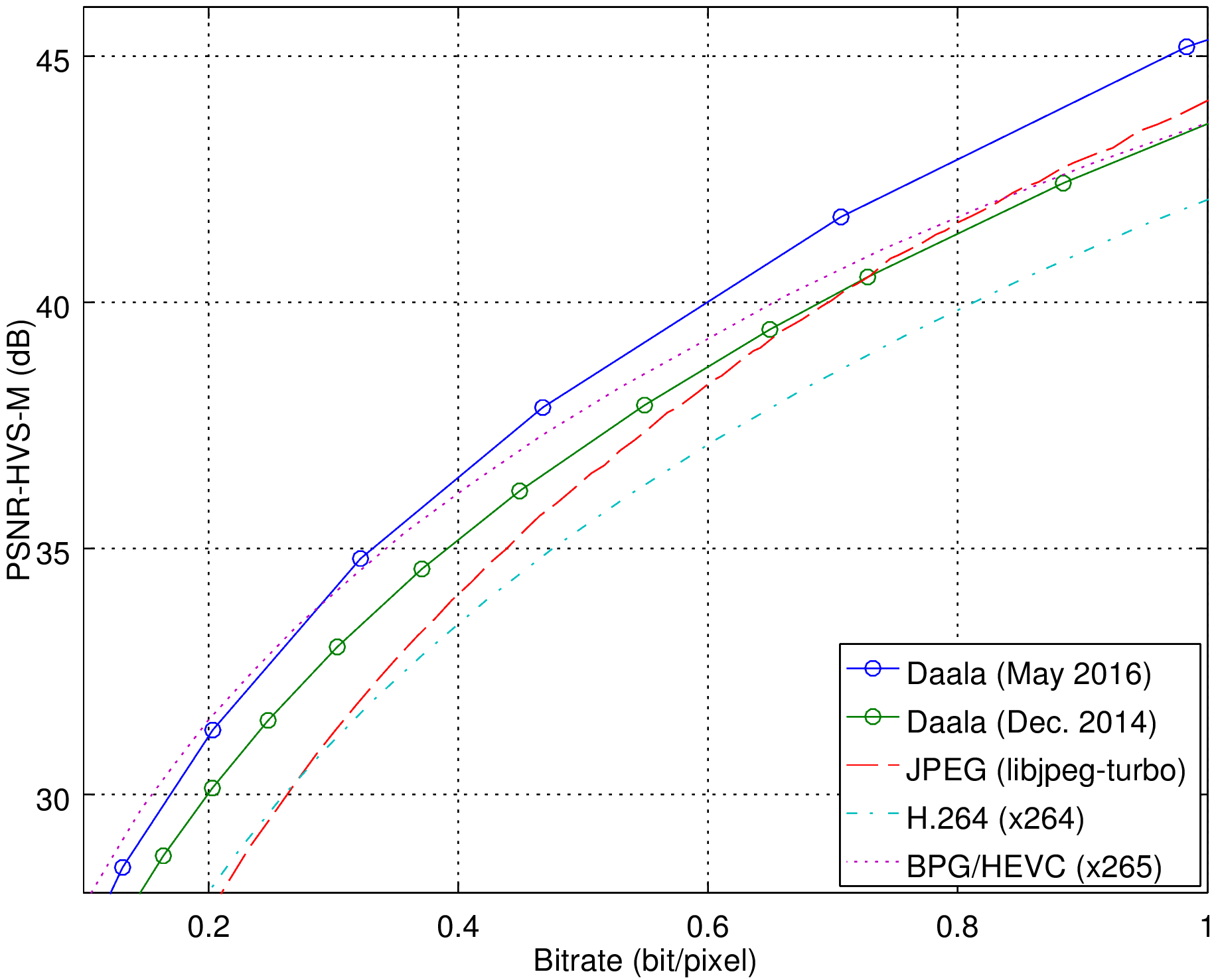
The improvement is around 20% this time. While it's not as spectacular as for video, it's still a significant improvement, enough to go from "slightly worse than HEVC" to "as good or slightly better than HEVC". On this metric anyway, and we all know that metrics aren't terribly accurate. So let's see how it actually looks like at equal rate compared to how we were 18 months ago.
Original Daala (May 2016) Daala (Dec. 2014) BPG (HEVC) WebP (VP8) JPEG

Low-bitrate comparison between Daala (now and 18 months ago), BPG (HEVC using x265 encoder), WebP (VP8) and JPEG (libjpeg-turbo) at the same rate.
You can also click here for a larger version of this demo, with more codecs.
The improvement in quality compared to the previous status update is quite obvious. Daala is now much better than both WebP and JPEG (libjpeg-turbo is the most commonly used JPEG encoder). As for Daala vs BPG/HEVC, the artifacts are obviously different and hard to judge from just four images. Opinions are likely to vary based on the viewer and the input image. At this point, what we'd really need is a full subjective test. Fortunately, this is exactly what is going to take place shortly, as Daala has been submitted as a candidate for the Image Compression Grand Challenge at ICIP 2016. The results should be available in September. In the mean time, you can read the paper we will be presenting.
—Jean-Marc Valin (jmvalin@jmvalin.ca) June 6, 2016